On this page we will give an overview of Terrier's main components and their interaction.
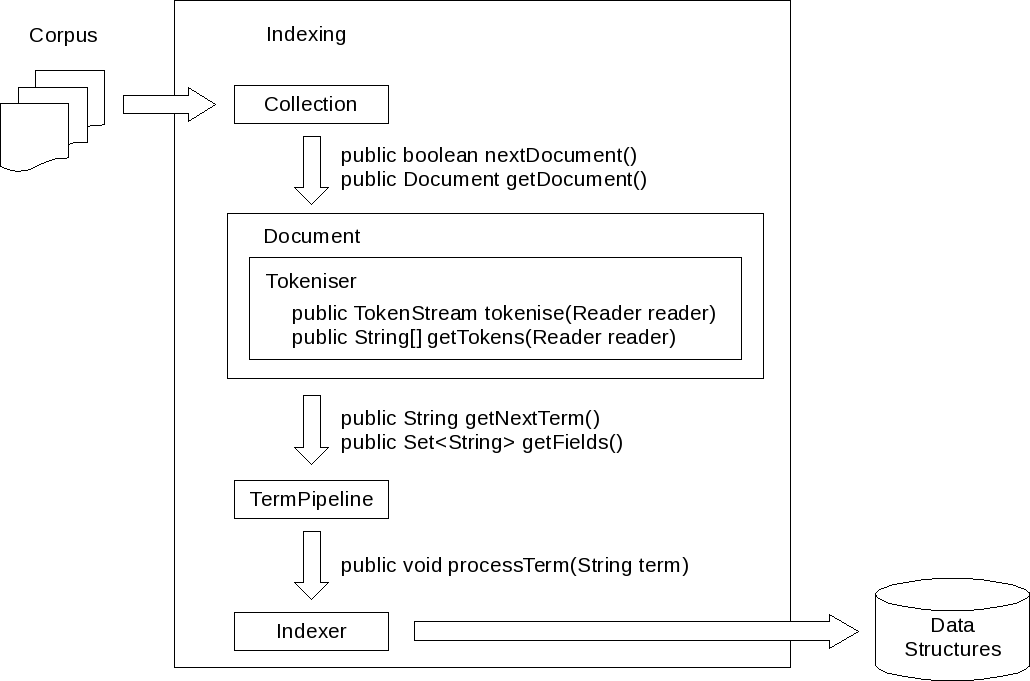
The graphic below gives an overview of the interaction between the main components involved in the indexing process.
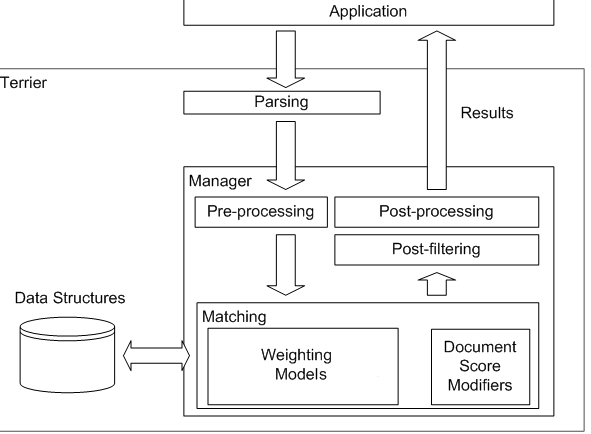
The graphic below gives an overview of the interaction of Terrier's components in the retrieval phase.
Here we provide a listing and brief description of Terrier's components.
| Name | Description |
|---|---|
| Collection | This component encapsulates the most fundamental concept to indexing with Terrier - a Collection i.e. a set of documents. See org.terrier.indexing.Collection for more details. |
| Document | This component encapsulates the concept of a document. It is essentially an Iterator over terms in a document. See org.terrier.indexing.Document for more details. |
| Tokeniser | Used by Document objects to break sequences of text (e.g. sentences) into a stream of words to index. See org.terrier.indexing.tokenisation.Tokeniser for more details. |
| TermPipeline | Models the concept of a component in a pipeline of term processors. Classes that implement this interface could be stemming algorithms, stopwords removers, or acronym expansion just to mention few examples. See org.terrier.terms.TermPipeline for more details. |
| Indexer | The component responsible for managing the indexing process. It instantiates TermPipelines and Builders. See org.terrier.structures.indexing.Indexer for more details. |
| Builders | Builders are responsible for writing an index to disk. See org.terrier.structures.indexing package for more details. |
| Name | Description |
|---|---|
| BitFile | A highly compressed I/O layer using gamma and unary encodings. See the org.terrier.compression packages for more details. |
| Direct Index | The direct index stores the identifiers of terms that appear in each document and the corresponding frequencies. It is used for automatic query expansion, but can also be used for user profiling activities. See org.terrier.structures.bit.DirectIndex for more details. |
| Document Index | The document index stores information about each document for example the document length and identifier, and a pointer to the corresponding entry in the direct index. See org.terrier.structures.DocumentIndex for more details. |
| Inverted Index | The inverted index stores the posting lists, i.e. the identifiers of the documents and their corresponding term frequencies. Moreover it is capable of storing the position of terms within a document. See org.terrier.structures.bit.InvertedIndex for more details. |
| Lexicon | The lexicon stores the collection vocabulary and the corresponding document and term frequencies. See org.terrier.structures.Lexicon for more details. |
| Meta Index | The Meta Index stores additional (meta) information about each document, for example its unique textual identifier (docno) or URL. See org.terrier.structures.MetaIndex for more details. |
| Name | Description |
|---|---|
| Manager |
This component is responsible for handling/coordinating the main high-level
operations of a query. These are:
|
| Matching | The matching component is responsible for determining which documents match a specific query and for scoring documents with respect to a query. See org.terrier.matching.Matching for more details. |
| Query | The query component models a query, that consists of sub-queries and query terms. See org.terrier.querying.parser.Query for more details. |
| Weighting Model | The Weighting model represents the retrieval model that is used to weight the terms of a document. See org.terrier.matching.models.WeightingModel for more details. |
| Document Score Modifiers | Responsible for query dependent modification document scores. See org.terrier.matching.dsms package for more details. |
| Name | Description |
|---|---|
| Trec Terrier | An application that enables indexing and querying of TREC collections. See org.terrier.applications.TrecTerrier for more details. |
| Desktop Terrier | An application that allows for indexing and retrieval of local user content. See org.terrier.applications.desktop package for more details. |
| HTTP Terrier | An application that allows for retrieval of documents from a browser. See src/webapps/results.jsp for more details, or the relevant documentation. |



Copyright © 2014 University of Glasgow | All Rights Reserved
